音声認識技術は近年、急速に進化しています。その中でも、WhisperというAIモデルが注目を浴びています。この記事では、Whisperの特徴や仕組み、そしてその利用シーンについて詳しく解説します。
Whisperの概要
- 開発元: オープンAI
- 目的: 高精度な音声からテキストへの変換
- 特徴: これまでの技術よりも高い精度を持つ
なぜWhisperが注目されているのか?
既存の技術との比較
- これまでの音声認識技術は、ノイズが多い環境や多様なアクセントに弱かった。
- Whisperは、そのような環境でも高い精度での変換が可能。
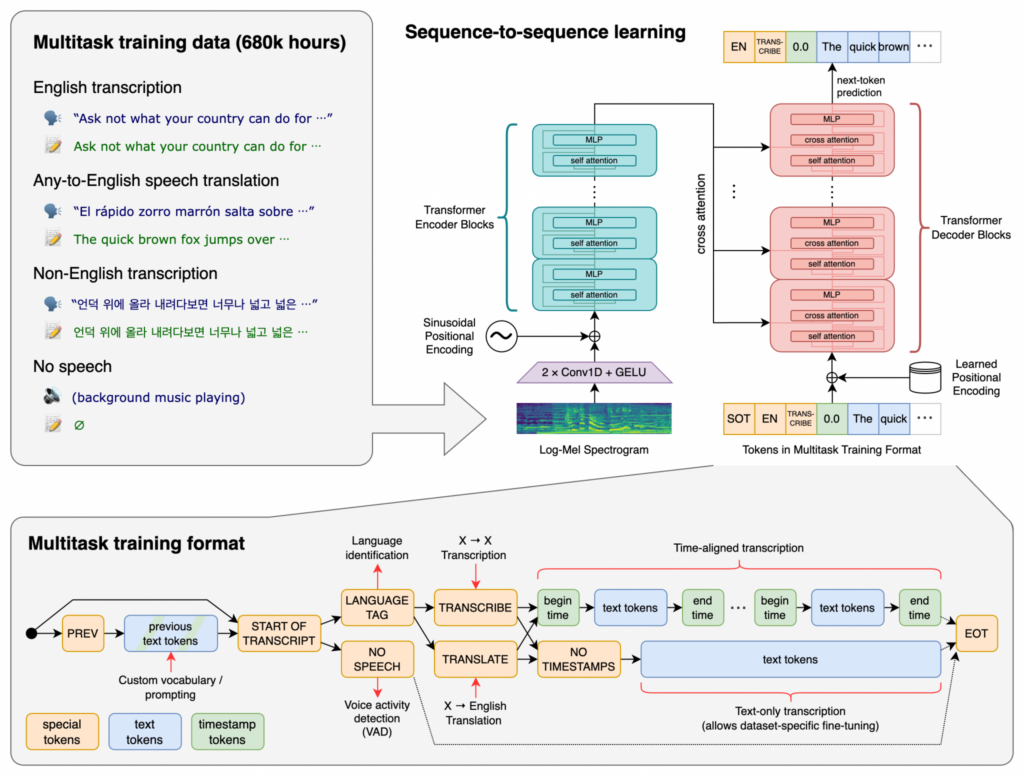
トランスフォーマーアーキテクチャの採用
- Whisperの背骨となるのは、トランスフォーマーアーキテクチャ。
- このアーキテクチャは、アテンション層を使ったエンコーダーとデコーダーの組み合わせで構成されている。
Whisperの仕組み
Whisperは、OpenAIが開発した音声認識モデルです。音声認識とは、音声データをテキストデータに変換する技術のことを指します。Whisperの仕組みは、以下のステップで構成されています:
- データ収集: Whisperの訓練のために、大量の音声データとその対応するテキストデータが収集されます。これにより、モデルはさまざまな言語、アクセント、環境ノイズなどの条件下での音声を理解する能力を獲得します。
- モデルの訓練: 収集されたデータを使用して、Whisperは音声とテキストの関係を学習します。この過程では、ディープラーニングの技術が使用され、モデルは音声のパターンを認識し、それをテキストに変換する方法を学びます。
- 音声の前処理: 音声データがWhisperに入力されると、まず前処理が行われます。これには、ノイズの除去や音声の正規化などが含まれます。
- 音声の分析: 前処理された音声は、Whisperによって分析されます。モデルは、音声の各部分を認識し、それに対応するテキストを生成します。
- テキストの出力: 最後に、Whisperは音声データをテキストデータに変換し、それを出力として提供します。
Whisperの特徴は、大量のデータと先進的なディープラーニング技術によって、高い精度で音声をテキストに変換する能力を持っていることです。また、さまざまな言語やアクセントに対応しており、多様な用途での利用が可能です。
Whisperの多言語対応
- 英語データが65%を占める中、日本語も高い精度での変換が可能。
- 他の言語に対しても、高い変換精度を持つ。
Google ColaboratoryでWhisperを体験してみよう!
Google Colaboratory(通常「Colab」として知られています)は、Googleが提供するクラウドベースのPython開発環境です。このツールを使用すると、ブラウザを通じてPythonコードを書き、実行することができます。特に、データ解析や機械学習のタスクに役立ちます。
Whisperについて: WhisperはOpenAIが開発した音声認識モデルで、音声をテキストに変換することができます。このモデルは、多言語の音声データを使用して訓練されており、高い精度で音声を文字起こしすることができます。
Google Colaboratoryで【Whisper】を体験する方法:
- Google Colaboratoryにアクセスし、新しいノートブックを開きます。
- 必要なライブラリやモジュールをインストールします。例えば、WhisperのPythonライブラリをインストールするためのコマンドを実行します。
- Whisperのモデルをロードします。
- 音声データをアップロードまたはリンクします。
- Whisperモデルを使用して、アップロードした音声データをテキストに変換します。
- 結果を確認し、必要に応じてさらなる分析や処理を行います。
Google Colaboratoryの利点:
- クラウドベース: ローカルマシンに何もインストールする必要がありません。
- 無料のGPUアクセス: 計算に時間がかかるタスクのための高速な計算能力。
- インタラクティブ: コードを書きながら即座に結果を見ることができます。
- 共有可能: 他のユーザーと簡単にノートブックを共有し、共同作業することができます。
このように、Google Colaboratoryは【Whisper】のような先進的なツールを手軽に試すのに適した環境を提供しています。
Whisper APIを利用するために必要なもの
Whisper APIを利用するために必要なものを以下に説明します:
- APIキー: OpenAIのWhisper APIを利用するためには、APIキーが必要です。このキーは、OpenAIの公式ウェブサイトから取得できます。APIキーは、リクエストの認証に使用されます。
- 適切なライブラリ: Whisper APIを簡単に利用するためのPythonライブラリやSDKが提供されています。これを使用すると、APIエンドポイントへのリクエストを簡単に行うことができます。
- 音声データ: Whisperは音声認識モデルなので、音声データが必要です。このデータは、APIリクエストとして送信され、テキストに変換されます。
- インターネット接続: APIはクラウドベースのサービスなので、インターネット接続が必要です。
- リクエストの制限: APIの利用には、リクエストの回数やデータのサイズなどの制限がある場合があります。公式のドキュメンテーションを参照して、制限の詳細を確認してください。
- 料金: Whisper APIの利用は、無料プランや有料プランが存在する場合があります。利用料金やプランの詳細については、OpenAIの公式ウェブサイトで確認してください。
- 公式ドキュメンテーション: APIの詳細な仕様や使い方、ベストプラクティスなどの情報は、公式のドキュメンテーションに記載されています。効果的な利用のために、ドキュメンテーションを参照することをおすすめします。
これらの要件を満たしていれば、Whisper APIを利用して、音声データをテキストに変換することができます。
YouTube動画をWhisper APIを利用して文字起こしする方法
- この動画では、新しくリリースされたOpenAIのWhisper APIを使用して、YouTube動画を文字起こしする方法を紹介している。
- YouTubeの動画から音源を抽出するために「ytdlp」というライブラリを使用し、その抽出したファイルをWhisper APIに渡して文字起こしを行う。
- 実際のデモでは、GPT-3や英語学習に関するYouTube動画を文字起こしの対象として使用している。
- Whisper APIは非常に高速で、約22分の動画を約1分で文字起こしすることができる。また、非常に正確に日本語の文字起こしが可能。
- APIキーを持っていれば、簡単にYouTube動画の文字起こしを行うことができると強調している。
まとめ
Whisperは、音声認識技術の新たな可能性を示しているAIモデルです。その高い精度と多様な応用性は、今後のAI技術の発展において大きな役割を果たすことでしょう。音声認識技術に関心のある方は、ぜひWhisperをチェックしてみてください。