GPTBotは、OpenAIが開発したウェブクローラーで、人工知能モデルの向上に向けてウェブ上のデータを収集します。この記事では、GPTBotの概要、機能、使用方法、倫理的な懸念、サイトオーナーへの影響などについて詳しく解説します。
GPTBotの概要

GPTBotは、OpenAIによって最近発表されたウェブクローラーで、GPT-4や今後のGPT-5などの人工知能モデルを向上させるためのデータ収集を目的としています。以下のような特徴があります。
1. データ収集の効率化
GPTBotは、ウェブ全体からさまざまな情報を効率的に収集し、AI技術の精度、能力、安全性の向上に貢献します。
2. 厳格なフィルタリング
OpenAIのポリシーに反する情報、有料ウォールに制限された情報、個人を特定可能な情報の収集を厳密に排除します。
サイトオーナーへの影響
GPTBotの運用は、ウェブサイトの所有者、すなわちサイトオーナーへのいくつかの重要な影響を及ぼします。
1. データのコントロール
サイトオーナーは、自分のウェブサイト上のどのディレクトリをGPTBotにクロールさせるか、あるいは禁止するかを決定できます。これにより、どの情報を共有するか、保護するかのコントロールが可能となります。
2. セキュリティとプライバシー
GPTBotは、個人情報を集めたり、OpenAIのポリシーに違反する情報源を避けるように設計されています。しかし、サイトオーナーとしては、自サイトのデータプライバシーとセキュリティに対する配慮が求められるでしょう。
3. 著作権と商業的考慮
GPTBotによってクロールされたデータが、商業的なAI製品の訓練に使われる場合、著作権や利益分配についての懸念が生じる可能性があります。サイトオーナーは、自分のコンテンツがどのように利用されるのかを検討する必要があるでしょう。
4. AI進化への貢献
GPTBotによるデータ収集に協力することで、サイトオーナーはAI技術の進化に直接的に貢献することができます。この進化は、将来的に様々な産業への応用が期待され、サイトオーナー自身にも恩恵をもたらすかもしれません。
5. 倫理的な問題
GPTBotの使用は、倫理的な議論も引き起こしています。サイトオーナーとしては、自身のウェブサイトのデータがどのように使われ、それが社会全体にどのような影響を及ぼすのかを考慮する必要があるでしょう。
GPTBotの運用は、サイトオーナーにとって多岐にわたる影響を持ちます。データのコントロールからセキュリティ、著作権、倫理的な問題に至るまで、慎重な考慮と対応が求められるでしょう。GPTBotの運用ガイドラインやOpenAIの方針に精通し、自身のサイトと合致する適切な対応を取ることが重要です。
倫理と法的な側面
GPTBotの運用には、倫理と法的な側面が深く関連しており、多岐にわたる議論と検討が必要です。
1. データプライバシー
GPTBotはウェブ上の情報をクロールしますが、個人情報の収集やプライバシーの保護は重要な法的課題です。OpenAIは、個人を特定できる情報の収集を避けるように設計されているとしていますが、この部分の法的コンプライアンスと透明性が求められます。
2. 著作権法
ウェブサイトのコンテンツのクローリングと使用は、著作権法に触れる可能性があります。特に、画像、音楽、動画などのメディアコンテンツが関わる場合、無許可での使用は著作権侵害となる可能性があります。
3. 商業利用と利益分配
GPTBotによって収集されたデータが商業製品の開発に利用される場合、その利益の分配についての倫理的な議論があります。ウェブサイトの所有者が自分のコンテンツが利益を生む目的で使用される場合、報酬や認知が求められることも考えられます。
4. 透明性と説明責任
GPTBotの運用においては、どのようなデータが収集され、どのように使用されるのかについての透明性が重要です。これに関連して、AIの倫理における説明責任の原則も関連するでしょう。
5. 公正な使用と社会的影響
GPTBotによるデータ収集と使用は、社会全体への影響も考慮する必要があります。例えば、データの偏りによって生じるバイアスなど、公正な使用に対する検討が必要です。
GPTBot はどのように機能するのでしょうか?
GPTBotはOpenAIによって開発されたウェブクローラーで、ウェブ上のデータを収集して人工知能モデルの精度、能力、安全性を向上させる目的で動作します。以下はその機能と働きについての詳細です。
1. データ収集
GPTBotは、ウェブ上からテキスト、画像、ビデオなどのデータを自動的に収集します。これらのデータは、AIモデルの訓練に使用されることで、より高度な精度と理解を達成するために役立ちます。
2. 厳格なフィルタリング
GPTBotは、特定の基準に基づいてデータをフィルタリングします。たとえば、有料のコンテンツ、OpenAIのポリシーに違反する情報、個人を特定可能な情報などは収集を避けるよう設計されています。
3. サイトオーナーとの協調
サイトオーナーは、robots.txtファイルを使用してGPTBotのアクセスを許可、制限、または禁止することができます。この柔軟性により、ウェブサイトのデータプライバシーとセキュリティを保護することが可能です。
4. 透明性の確保
GPTBotは、特定のユーザーエージェントトークンと文字列を使用して、ウェブサイト管理者がそのトラフィックを識別できるようにしています。また、IPアドレスの範囲もOpenAIのウェブサイトで公開されており、トラフィック源に対する透明性を提供します。
5. 法的・倫理的な配慮
GPTBotは、著作権、ライセンス、その他の法的・倫理的な問題に対しても注意深く設計されています。OpenAIは、データの収集と使用における透明性と倫理性を重視しています。
GPTBotは、データ収集、厳格なフィルタリング、サイトオーナーとの協調、透明性の確保、法的・倫理的な配慮などを通じて機能します。これらの特性により、GPTBotはAIの未来を形作るためのデータを効率的かつ責任を持って収集する重要なツールとなっています。
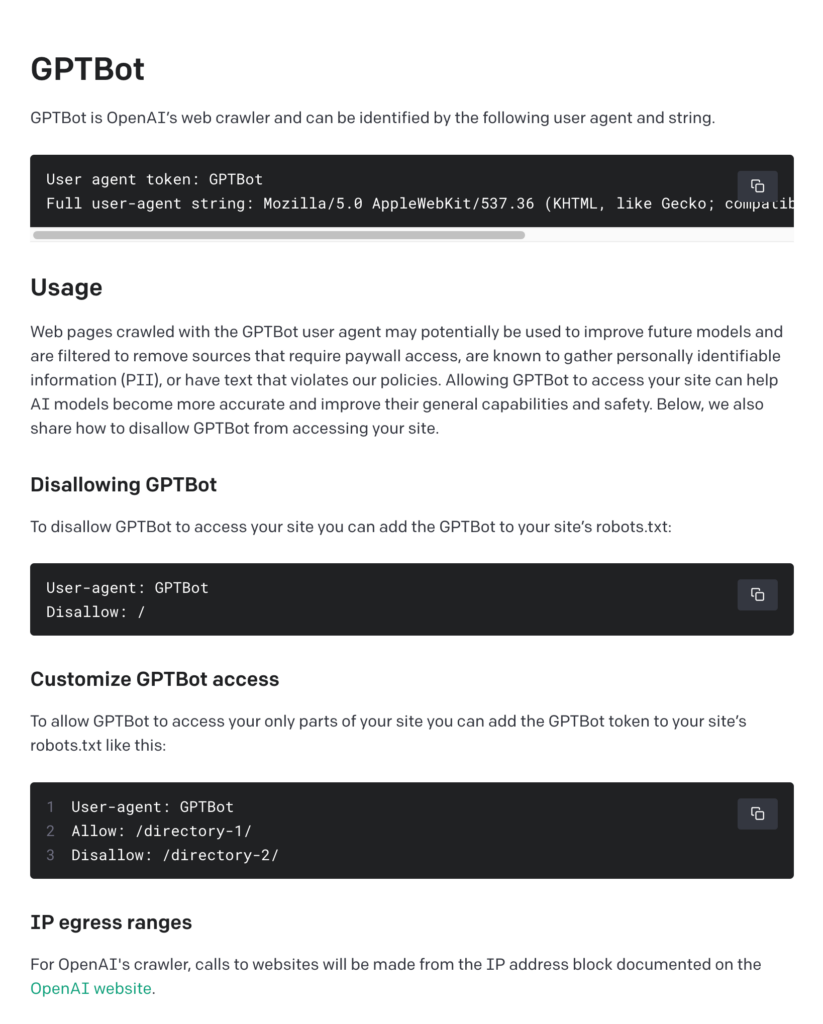
GPTBotを禁止するにはどうすればよいですか?
GPTBotをウェブサイトから禁止するには、特定の指示をrobots.txtファイルに追加する必要があります。以下はその手順です。
1. robots.txtファイルの編集
ウェブサイトのルートディレクトリにあるrobots.txtファイルを開きます。このファイルがない場合は、新しく作成することができます。
2. GPTBotへのアクセス禁止の記述
robots.txtファイルに以下の記述を追加します。
User-agent: GPTBot
Disallow: /この記述により、GPTBotのユーザーエージェントがサイト全体にアクセスすることが禁止されます。
GPTBot がアクセスできるディレクトリをカスタマイズする方法
GPTBotがアクセスできるディレクトリをカスタマイズする方法は、ウェブサイトのルートディレクトリにあるrobots.txtファイルを編集することで実現できます。以下は、その手順と例です。
1. robots.txtファイルの編集
ウェブサイトのルートディレクトリに位置するrobots.txtファイルを開きます。もし存在しない場合、新しく作成します。
2. GPTBotへのアクセス許可・禁止の指定
GPTBotに対して特定のディレクトリへのアクセスを許可または禁止するために、以下のような記述を追加します。
User-agent: GPTBot
Allow: /directory-1/
Disallow: /directory-2/この例では、GPTBotに対して/directory-1/へのアクセスを許可し、/directory-2/へのアクセスを禁止しています。
上記のrobots.txtファイルの記述は、ウェブサイト上でGPTBotがアクセスできるディレクトリを指定しています。具体的には、次のような設定がされています。
Allow: /directory-1/により、GPTBotは/directory-1/というディレクトリにアクセスすることが許可されます。Disallow: /directory-2/により、GPTBotは/directory-2/というディレクトリにアクセスすることが禁止されます。
この設定によって、ウェブサイトの管理者は、GPTBotがアクセスできる内容を細かくコントロールすることができます。特定のディレクトリに対してアクセスを許可し、他のディレクトリに対してアクセスを制限することができます。
このような設定は、サイトの特定のセクションをクローリングボットから保護したい場合や、特定のコンテンツのみをAIモデルの訓練データとして提供したい場合などに役立つでしょう。
3. 保存とアップロード
変更を保存した後、robots.txtファイルをサーバーにアップロードします。
注意点
AllowおよびDisallowの指定は、ディレクトリの階層やパスに応じて複数追加することができます。- 指定を誤ると他のウェブクローラーへのアクセスも誤って制限する可能性があるため、慎重に編集してください。
- この変更は、GPTBotだけに影響します。他のクローラーに対する設定も必要な場合は、それらのユーザーエージェントに対して別途指定する必要があります。
このようにして、ウェブサイトの所有者や管理者は、GPTBotがアクセスできるディレクトリをカスタマイズし、特定の情報を共有したり保護したりすることができます。
3. 保存とアップロード
変更を保存し、必要に応じてサーバーにアップロードします。
注意点
- ウェブサイトの設定によっては、
robots.txtファイルへのアクセス権限が必要になる場合があります。適切な権限を持っていることを確認してください。 robots.txtファイルの誤った編集は、他のウェブクローラーに対するアクセスも誤って制限する可能性があるため、慎重に編集する必要があります。
この設定により、GPTBotはあなたのウェブサイトにアクセスすることができなくなります。最新の情報や専門的なサポートが必要な場合は、ウェブ開発者や専門家に相談することも考慮に入れるとよいでしょう。
GPTBotの今後の展望

GPTBotは、AIモデルの訓練データを収集するための新しいクローリングシステムで、OpenAIによって展開されています。この先進的な技術の今後の展望には、以下のような点が挙げられます。
1. AIモデルの改善
GPTBotによって収集されるデータは、GPT-4や今後のGPT-5などのAIモデルを更に高精度にするために利用されるでしょう。これにより、自然言語処理、画像認識、音声認識などの分野でのAIの性能が向上すると期待されます。
2. 透明性と倫理の強化
GPTBotの運用には、データプライバシー、セキュリティ、著作権などの法的・倫理的な問題が絡むため、今後も透明性と倫理の強化が求められるでしょう。OpenAIがどのようにこれらの問題に対応していくのかが、今後の展開の鍵となるでしょう。
3. カスタマイズとコラボレーションの拡大
GPTBotのアクセスをカスタマイズする能力は、ウェブサイト管理者とOpenAIとの協力の新しい形を生み出します。今後、より多くのサイトとのコラボレーションが進展し、多岐にわたるデータの収集が進むことが期待されます。
4. 商業的応用の可能性
GPTBotによるデータ収集は、商業分野でも新しいチャンスを創出するかもしれません。例えば、市場調査、トレンド分析などの応用が考えられます。
5. 技術の進化と挑戦
GPTBotの技術は進化し続けるでしょうが、同時に新しい挑戦も現れる可能性があります。データの質の確保、偽情報のフィルタリング、国際的な法規制の遵守など、解決すべき課題も多く残されているでしょう。
- OpenAIは新しいクローラー「GPTBot」を開発。このクローラーはWebページを巡回して情報を収集するプログラムで、Googlebotなどと同じようなもの。
- GPTBotの目的は、ネット上から収集した情報をAIモデルの学習や改善に使用すること。
- もし何も設定しなければ、自分のウェブサイトのデータがOpenAIのAIに学習のために使われる可能性がある。
- ウェブサイト運営者は、自分のサイトがGPTBotにクロールされることを拒否することができる。拒否方法はロボットテキストを使用して設定可能。
- 現時点でGPTBotによるクローリングを許可する明確なメリットはないが、Googleのクローラーの場合はそのメリットが存在する。
まとめ
GPTBotは、AIモデルの進展における革新的なステップであり、多くの機会と課題を提供します。ウェブサイトの所有者や開発者、データサイエンティストなどにとって、GPTBotに対する理解と適切な対応は今後ますます重要になると考えられます。
今後のAIの発展とともに、GPTBotに関連する法的、倫理的な議論は深まり、その結果が今後のウェブとAIの関係を形成するでしょう。最新の情報を追いかけ、適切な判断と対応を行うことが、GPTBotを最大限に活用し、そのリスクを最小限に抑える鍵となるでしょう。