ELYZAは、最新の技術と言語モデリングを駆使し、商用利用可能な日本語LLM「ELYZA-japanese-Llama-2-7b」を公開しました。この革新的なモデルは、日本語の自然なコミュニケーションを支援し、さまざまな用途で活用される可能性を秘めています。本記事では、「ELYZA」の特徴や利点、その背後にある技術について詳しく解説します。
自然言語処理(NLP)技術の進化は、人機間のコミュニケーションに大きな変革をもたらしています。その一翼を担う商用利用可能な日本語LLM「ELYZA」が、その先駆的な存在として注目されています。ELYZAは、日本語におけるコミュニケーションの向上と、多岐にわたる用途での応用を目指して開発されました。
ELYZAの特徴
基盤となる「Llama 2」
ELYZAの基盤となっているのは、「Llama 2」という言語モデルです。Meta社が開発した「Llama 2」は、英語ベースの大規模な言語モデルであり、その性能は非常に高い評価を受けています。これをベースにして、ELYZAは日本語に特化したモデルを開発しました。
事前学習と事後学習
ELYZAは、「ELYZA-japanese-Llama-2-7b」というモデルを開発しました。これは「Llama 2」を元に、日本語による追加事前学習を施したものです。さらに、「ELYZA-japanese-Llama-2-7b-instruct」というモデルでは、ユーザーからの指示に従って様々なタスクを解決する能力を獲得しました。この事後学習には、ELYZA独自の高品質な指示データセットが用いられており、対話形式のコミュニケーションをサポートします。
日本語語彙の拡充
日本語の言語モデリングにおいて、語彙の豊富さは非常に重要です。元々の「Llama 2」は英語に特化しているため、日本語の語彙が不足していました。そこで、ELYZAは約13,042個の日本語の語彙を追加し、「ELYZA-japanese-Llama-2-7b-fast」として新たなモデルを開発しました。これにより、日本語文章のトークン数が削減され、推論速度が向上しました。
ELYZAの利用可能性
商用利用への展開
ELYZAの最大の特徴のひとつは、商用利用が可能であることです。Llama 2 Community Licenseに基づいてライセンスが提供されており、研究からビジネスまで幅広い分野で活用が期待されています。このモデルを活用することで、顧客対応、自動応答、情報検索などの用途で効果的に活用できます。
研究と開発の支援
ELYZAは、日本語LLMの研究と開発を加速することを目指しています。独自のモデルとデータセットの公開により、研究機関やスタートアップ、個人が日本語の自然言語処理技術を進化させる土壌を整備しています。また、技術ブログなどを通じて、エンジニアや研究者が新たな知見を得る手助けも行っています。
ELYZA Tasks 100による評価
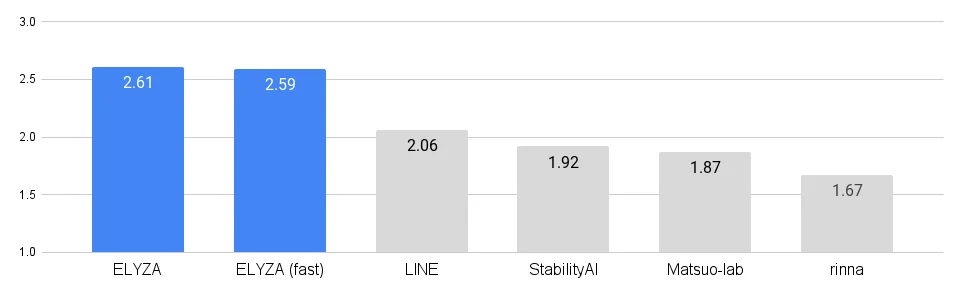
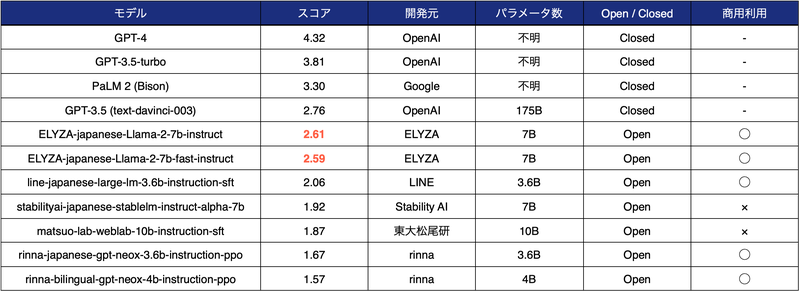
「ELYZA Tasks 100」という評価用データセットが用意されています。このデータセットは、多様な日本語タスクを含み、ELYZAの性能を客観的に評価するためのものです。自動評価だけでなく、人間による評価も行われ、その結果を通じてELYZAの高い性能が示されています。
将来展望
「ELYZA-japanese-Llama-2-7b」は、日本語LLMの分野において革新的な進化をもたらすものとして、今後の展望が非常に期待されています。研究やビジネスの分野で活用され、さらなる進化を遂げることで、日本語の自然言語処理技術はますます進化していくことでしょう。
ELYZAは、日本語のコミュニケーションにおける新たな未来を切り拓く先駆者として、ますます注目を浴びています。その高性能な機能や商用利用可能性を通じて、日本語圏のNLP技術の発展に大きな寄与を果たすことは間違いありません。今後の展開に注目です。
性能評価
性能評価は、コンピュータープログラムやシステムの動作や効果を客観的に評価するプロセスを指します。特定のタスクや目標に対するパフォーマンスを測定し、その結果を分析してシステムの品質や能力を評価することが目的です。自然言語処理(NLP)分野においても、性能評価は重要な役割を果たしています。
ELYZA Tasks 100とは何ですか?
ELYZA Tasks 100は、ELYZAの性能評価を行うために用意された評価用データセットです。このデータセットには、さまざまな日本語タスクが含まれており、ELYZAがどの程度の精度でタスクを遂行できるかをテストするのに使用されます。ELYZA Tasks 100は、実際のタスクやシナリオに基づいて構築されており、現実的な評価を提供することが狙いです。
lm-evaluation-harnessとは何ですか?
lm-evaluation-harness(言語モデル評価ハーネス)は、言語モデルの性能評価を行うためのツールやフレームワークのことを指します。このツールは、NLPコミュニティにおいて広く使用されており、異なるモデルやデータセットを用いて性能評価を行う際に、一貫性のある結果を得るために役立ちます。lm-evaluation-harnessは、正確な比較や評価指標の計算を支援する役割を果たしています。
性能評価においては、ELYZA Tasks 100とlm-evaluation-harnessの組み合わせが、ELYZAの能力や弱点を明確に示す重要なツールとなります。これにより、ELYZAの改善点や進化の方向性を把握し、より高度な自然言語処理技術の開発に貢献することが期待されています。
使用方法とは何ですか?
使用方法とは、特定のツール、製品、サービス、またはシステムをどのように利用するかを指す言葉です。これは、ユーザーがそれらのリソースを適切に活用し、目的を達成するための手順や方法を理解するために重要な情報です。使用方法は、効率的で効果的な操作を実現するために必要な手順やガイドラインを提供します。
「ELYZA」の使用方法とは?
「ELYZA」の使用方法は、日本語の自然言語処理モデルを効果的に活用するための手順やガイドラインを指します。ユーザーが「ELYZA」を最大限に活用するためには、以下のステップが含まれます:
- モデルの取得: 「ELYZA」を使用するには、適切なライセンスを取得し、モデルにアクセスする必要があります。ライセンスやアクセス方法についての情報を確認してください。
- APIの統合: もしAPIを介して「ELYZA」を利用する場合、APIキーの取得と統合が必要です。APIキーを取得し、ドキュメントやガイドを参考にしてAPIをプロジェクトに統合します。
- コードの実装: 使用したいプロジェクトに適したプログラミング言語(Pythonなど)を使用して、モデルを呼び出すコードを実装します。APIのエンドポイントやパラメータを適切に指定してモデルにアクセスします。
- 入力データの準備: 自然言語のテキストデータを「ELYZA」に提供するために、適切な入力フォーマットを準備します。入力テキストの長さや構造に注意を払い、モデルが正確な結果を返すようにします。
- API呼び出しと応答の解析: コードを使用してAPIを呼び出し、モデルからの応答を受け取ります。応答データを解析し、必要な情報や結果を抽出します。
- 応用と活用: モデルの応答を自分のプロジェクトやアプリケーションに活用します。顧客対応、文章生成、情報検索など、さまざまな用途で「ELYZA」を活用することができます。
使用方法の理解は、「ELYZA」の効果的な活用に不可欠です。正確な手順やガイドに従って操作することで、自然なコミュニケーションや情報処理において最適な結果を得ることができます。
今回公開された4つのモデルは、Hugging Face Hubにて公開されており、transformersライブラリを通じて利用することができます。これらのモデルを効果的に活用するための詳細な使用方法は、以下のリンク先のREADMEページで確認できます。
- ELYZA-japanese-Llama-2-7bの使用方法
- ELYZA-japanese-Llama-2-7b-instructの使用方法
- ELYZA-japanese-Llama-2-7b-fastの使用方法
- ELYZA-japanese-Llama-2-7b-fast-instructの使用方法
これらのリンク先のREADMEには、各モデルの詳細な説明や、使用方法、サンプルコードなどが提供されています。以下は、使用方法の大まかな概要です。
- 必要なライブラリのインストール:
transformersライブラリをインストールします。ターミナルやコマンドプロンプトで、以下のコマンドを実行します。
pip install transformers
- モデルの読み込みと利用:
transformersライブラリを使用して、各モデルを読み込んで利用します。具体的なコード例は、各READMEに提供されています。 - テキストの生成や処理: モデルを使用して、テキストの生成や処理を行います。入力テキストをモデルに渡し、モデルからの応答を受け取ります。
- 応用: 必要に応じて、モデルの応答をプロジェクトやアプリケーションに統合し、日本語の自然なコミュニケーションやタスクをサポートします。
各モデルのREADMEには、さらに詳細な手順やオプション、サンプルコードが提供されているため、具体的な使用方法を理解し、効果的にモデルを活用することができます。
まとめ
「ELYZA」の公開により、商用利用可能な日本語の自然言語処理モデルが提供されました。このモデルは、「Llama 2」をベースに日本語に特化した事前学習を行い、高度な言語処理能力を持つことが特徴です。以下にまとめます。
- ELYZAの概要: 「ELYZA」は、Metaの「Llama 2」を基に開発された日本語の自然言語処理モデルです。商用利用が可能であり、日本語のコミュニケーションやタスクに活用されることを目指しています。
- モデルの種類: ELYZAでは、いくつかのモデルが公開されています。その中には、事前学習と事後学習が組み合わさったモデルや、高速化を実現したモデルなどが含まれています。
- 使用方法: ELYZAのモデルは、Hugging Face Hubから利用可能です。各モデルのREADMEには、詳細な使用方法やサンプルコードが提供されており、効果的な活用が可能です。
- 性能評価: ELYZA Tasks 100という評価用データセットを用いて、ELYZAの性能評価が行われています。自動評価だけでなく、人間による評価も行われ、高い性能が示されています。
「ELYZA」の公開により、日本語の自然言語処理技術の進化が促進されることが期待されます。研究者や開発者、ビジネスの分野で「ELYZA」を活用し、さまざまなタスクやプロジェクトにおいて高度な言語処理を実現する可能性が広がっています。